ホームページから情報を抽出することを、Webスクレイピングと呼びます。実は、ExcelでもWebスクレイピングができます。
Power Queryという機能を使用することで、Webから情報を抽出できます。例:
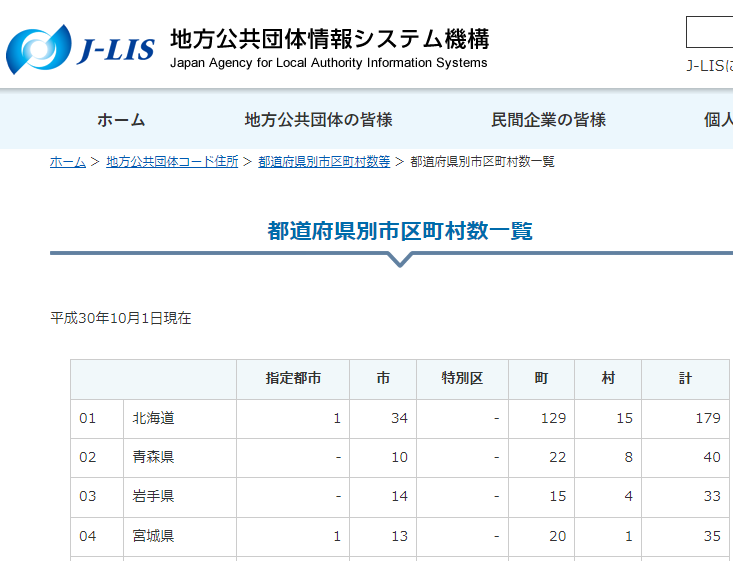
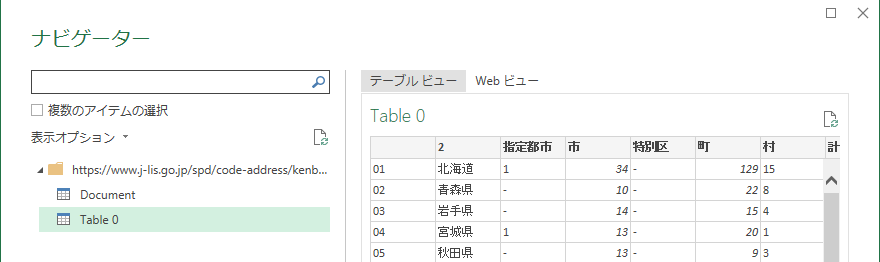
しかし、抽出できるのページ内のテーブル要素だけです。
以下のページのように、欲しい情報がテーブルではなくリストに格納されている場合は抽出できません。
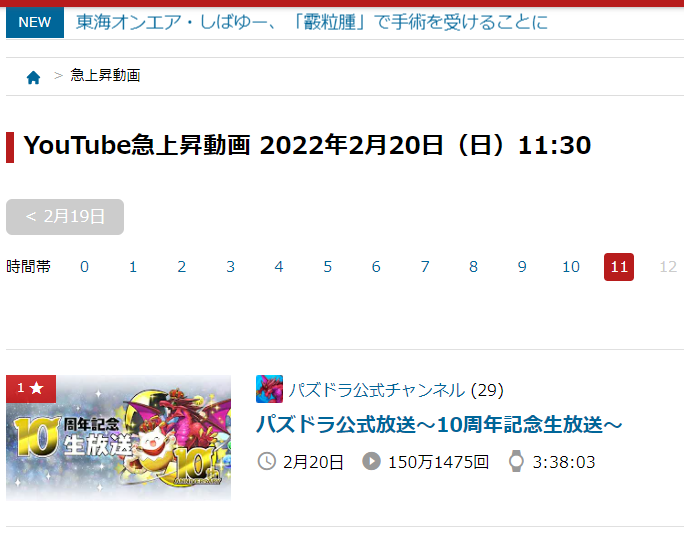
https://ytranking.net/trend/
そこで、リスト要素であっても情報を抽出する方法をご説明します。
処理の流れ
欲しい情報を抽出するため、ページを文字列として読み込み、サイトの構造に合わせて加工していきます。
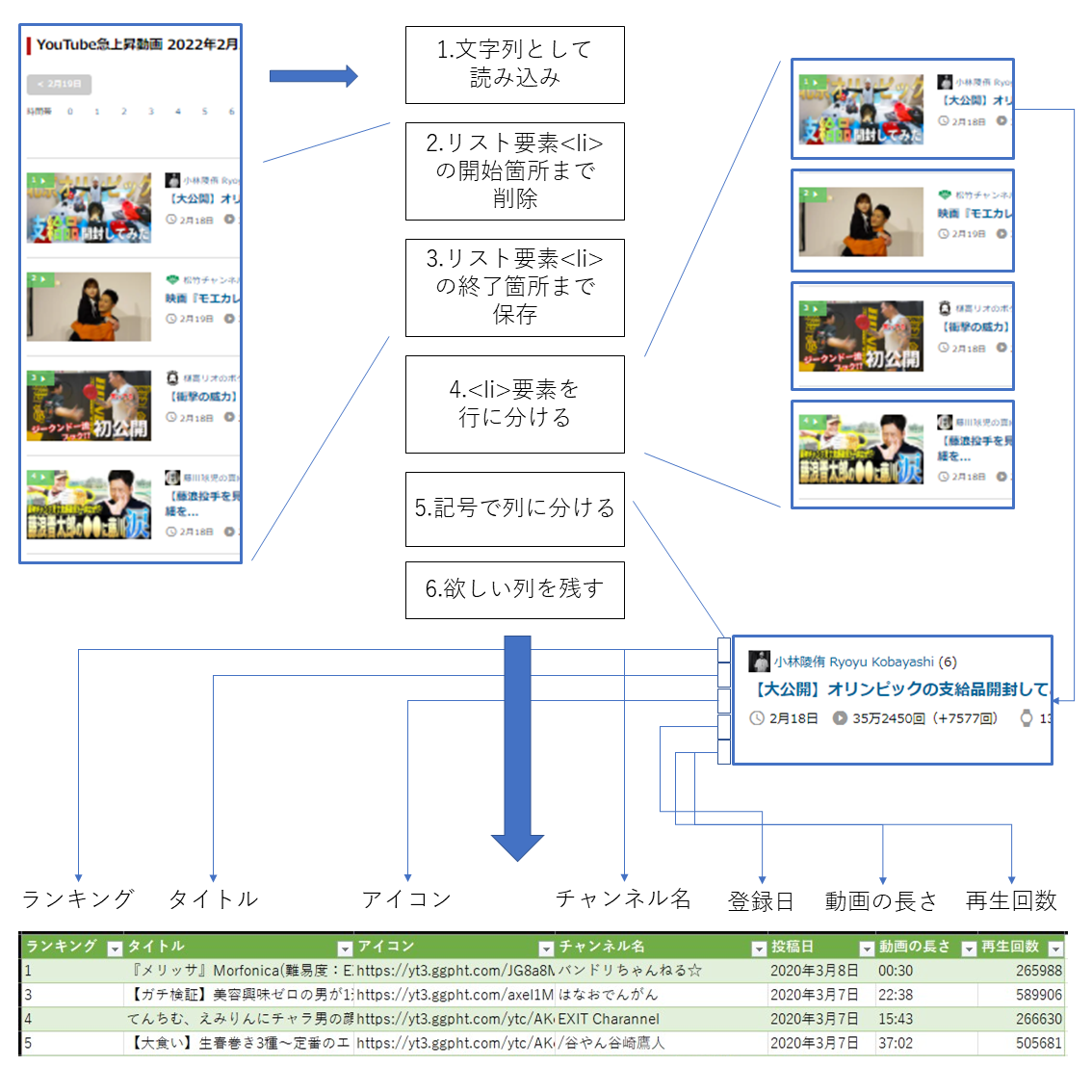
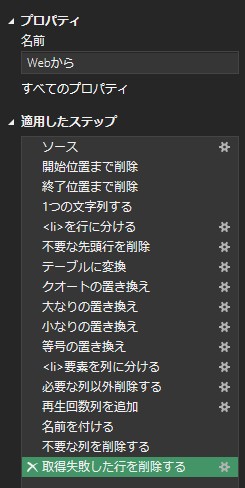
1.文字列として読み込み
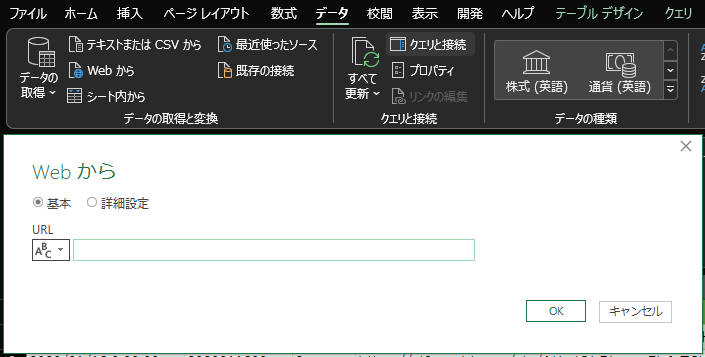
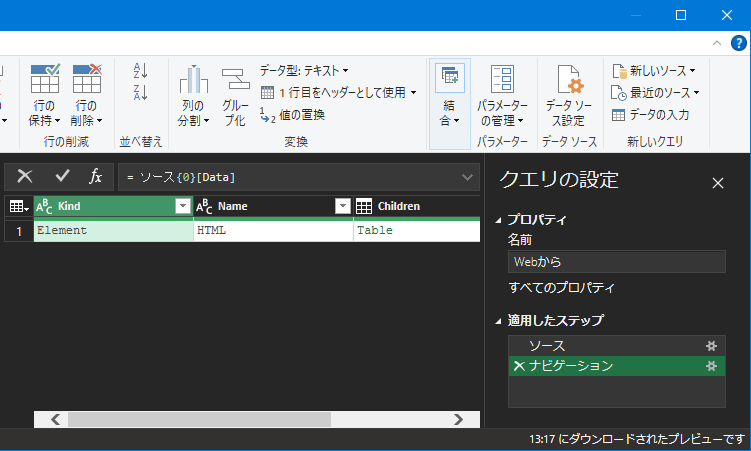
記事の最初のほうの手順と同じく、「Webから」を選び、URLを入力します。
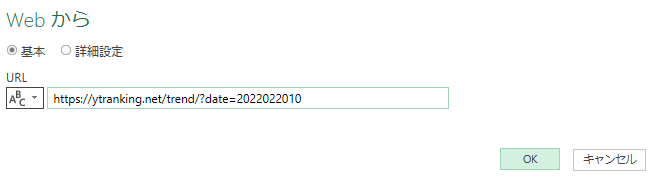
文字列として読み込みたいので、「データの変換」をクリックし、処理を編集していきます。


2.リスト要素<li>の開始箇所まで削除
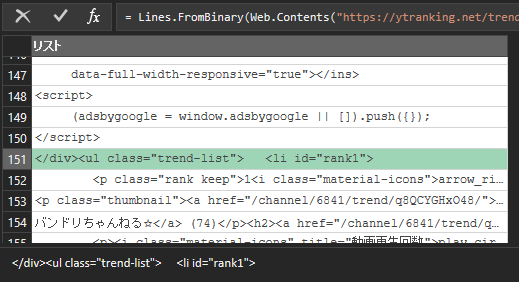
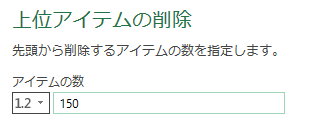
読み込まれたhtmlソースをスクロールしていき、抜き出したいデータの開始位置を探します。151行目が<li>要素の開始位置でした。
先頭150行は不要なので削除します。
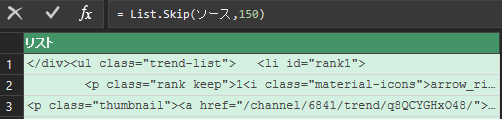
しかし、これではサイトに何か変更があり、<li id=”rank1″>が151行目で無くなったら処理がうまくいかなくなります。
そこでList.Skip(ソース,150)を書き換えていきます。
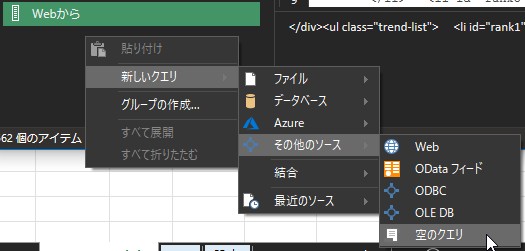
最初に<li id=”rank1″>がでてくるまで削除したいので、List.RemoveFirstN を使用します。
最初に残したい行の文字列をコピーします。
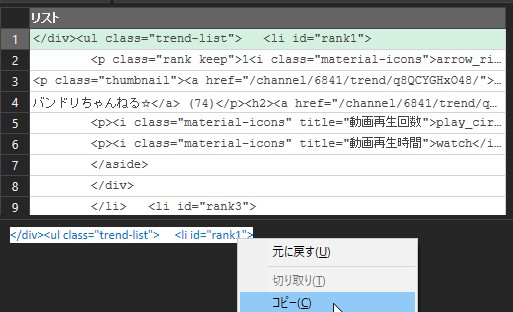

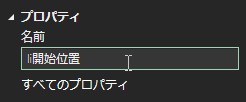
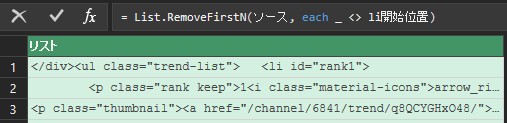
書き換えても結果が変わらない(1行目に<li id=”rank1″>があることを確認してください。これで、最初のliタグが151行目でなくても、望んだ結果がえられるようになりました。
3.リスト要素<li>の終了箇所まで保存
同じように、liの終了位置を探します。
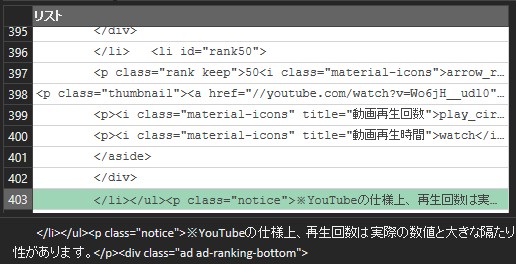

後ろから159行削除します。
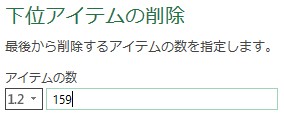
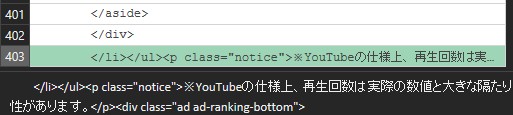
同じく、不要な行が159行でなくなると、後の処理がうまくいかなくなるため、開始位置と同様に改善します。
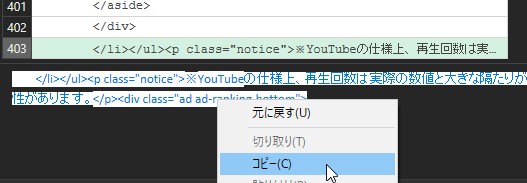
同様に、新しいクエリを作成して「li終了位置」と名前を付けておきます。

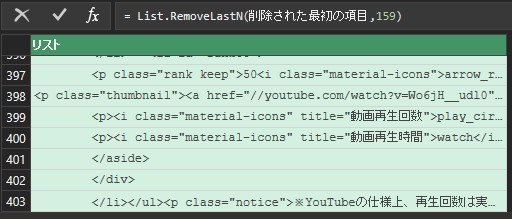
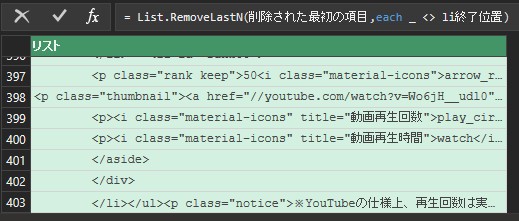
結果が変わらないことが確認できます。
4.<li>要素を行に分ける
今のリストは、htmlソースの元々の改行位置で行が分かれているので、一度すべての行を一つの文字列に結合してから、<li>で分割します。
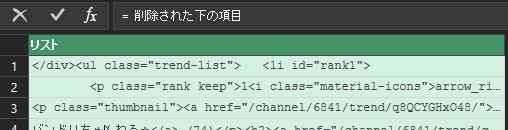
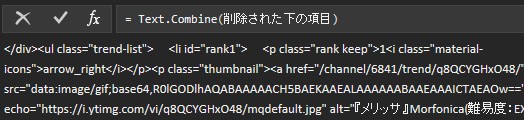
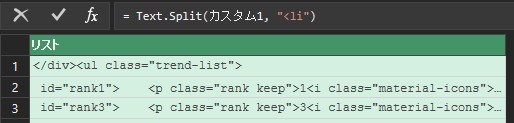
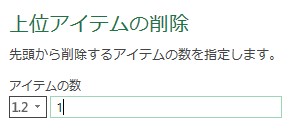
1行目は不要なので、1行削除します。
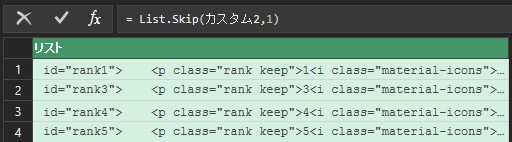
5.記号で列に分ける
要素を行に分けられたので、要素の中身を列に分けます。分ける記号は「 ” , = , > , < 」の四つです。

次に、それぞれの記号を一つの別の記号「 @ 」に置き換えます。

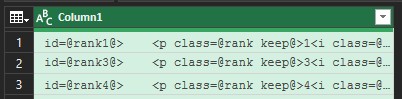
他3つの記号についても同じく置き換えます。
次に、「 @ 」で列に分割します。
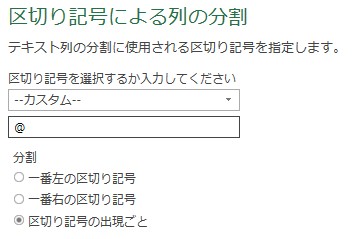
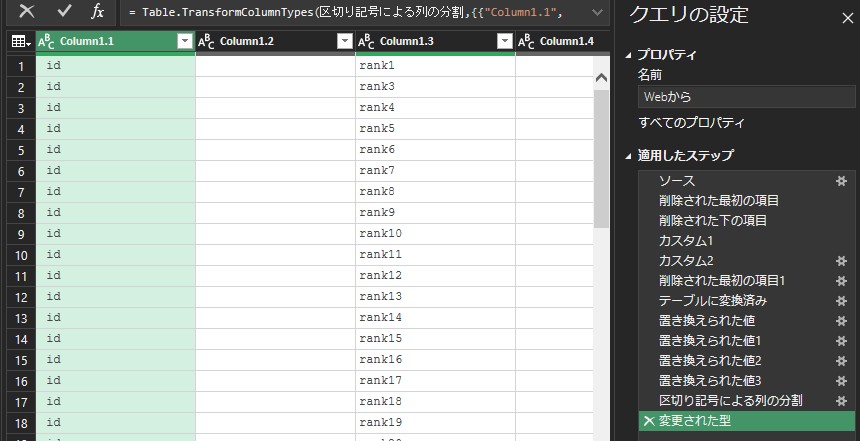
6.欲しい列を残す
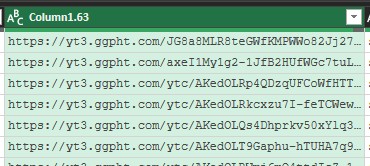
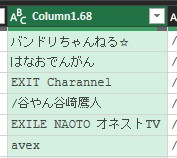
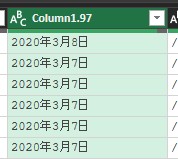
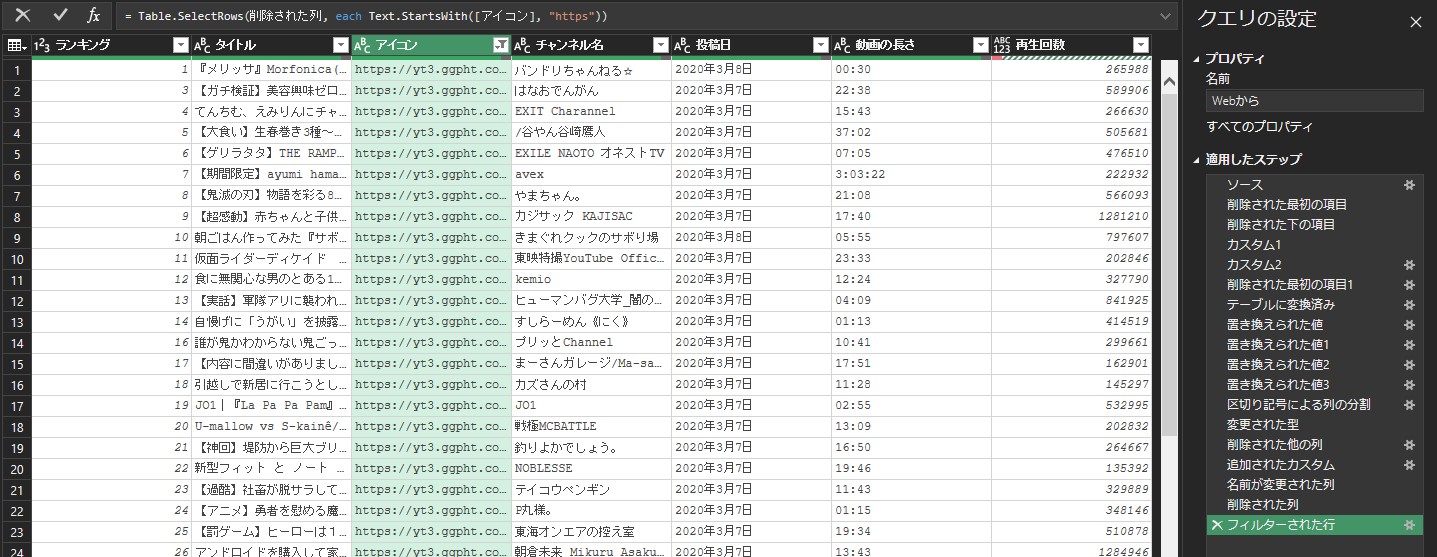
今回、抽出したい列は、「ランキング」、「タイトル」、(チャンネルの)「アイコン」、「チャンネル名」、「登録日」、「動画の長さ」、「再生回数」の7列です。分割後の列から、これら情報がある列を選択します。

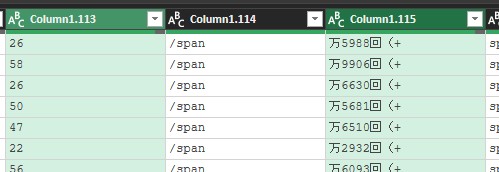

再生回数だけ、万以上と以外で分かれているので、これを結合した列を作成します。
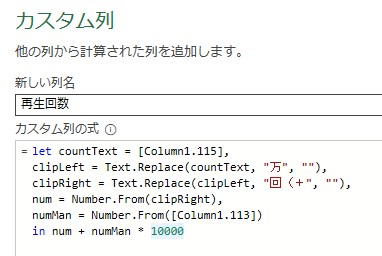
let countText = [Column1.115],
clipLeft = Text.Replace(countText, “万”, “”), // 万単位以外の数値の前後、万、回(+を消す
clipRight = Text.Replace(clipLeft, “回(+”, “”),
num = Number.From(clipRight), // 数値化
numMan = Number.From([Column1.113])
in num + numMan * 10000 // 万単位の数字を10000倍して足す

列名がまだColumnと内容を表せていないので、ここで名前を付けます。

不要な列(再生回数の元の列)を削除します。
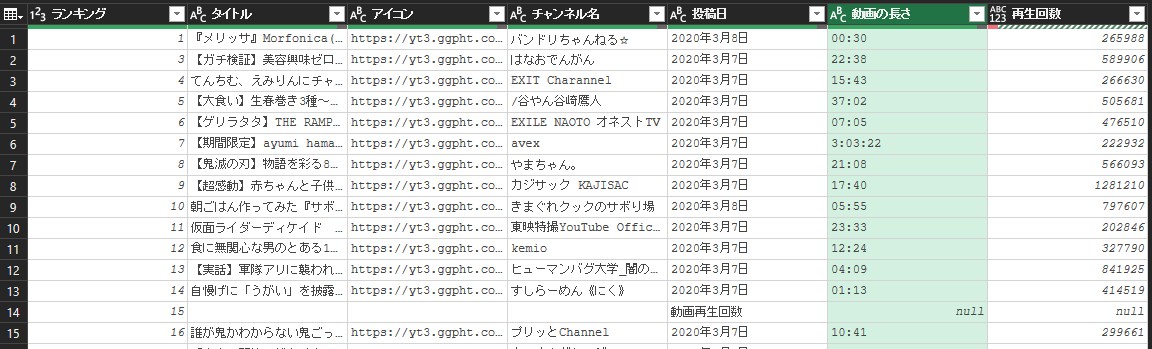
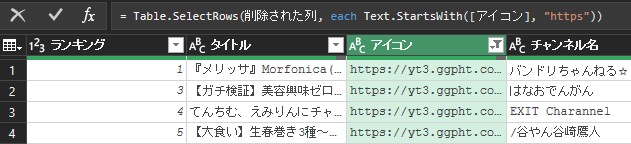
ここで14行目が思った結果が取れていないことがわかったので、行を削除します。条件として、アイコン列がhttpsで始まっていないものとします。

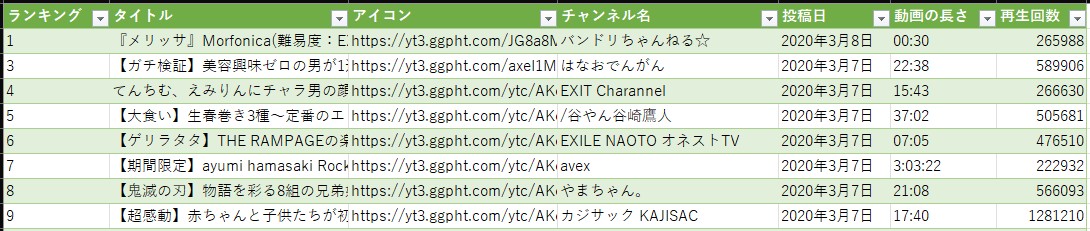
いかがでしたか?マウスの操作と、少しのPower Queryの関数の知識で、htmlソースから、欲しい情報を取り出す方法を説明しました。
今後、URLが連番で変化するページや、ページの更新部分を読み込む方法などを説明していきます。

コメント